
第1回パネルディスカッション「生成AIと声」後編
- ●生成AIとの共存に向けた提案
久保田氏
それでは、生成AIとの共存に向けた提案について考えていきたいと思います。田邉さんの話では、法的な保護が難しいという指摘でしたが、教育や啓蒙という観点からも、著作権者の保護に向けた取り組みを考えていけると幸いです。
池水氏
「声」には保護される法律がないと言われていますが、2024年11月13日に音声業界からは3つの声明を出しています。
・生成AI音声を、アニメーション及び外国映画等の吹替では使用しないことを求める
・生成AI音声を学習・利用する際は、本人の許諾を得ることを求める
・生成AI音声には、AIによる生成物であることの明記を求める
海外では、AIの学習には事前に本人の許諾が必要だというお話がありました。AIによる生成物の明記は、はっきりしてもらいたいです。AIを自分だと思われたくはないのです。演技の領域は、人間こそが行うべきものと確信しております。国際俳優連合のガイドラインでも、インフォームドコンセントが必要とされていますが、日本では対応が遅れているので、日本政府へ業界として啓発活動を進めてまいります。俳優や声優は、単なるデジタルで喋る機械ではなく、実演家として個人の人格が尊重されるべきだと考えます。ある声優の声が無断で収集されてネットで不正に利用されてしまえば、それに反応して炎上する心配もあります。そのときに、本来ならば生成AIを不正に利用した者が非難の対象になるはずですが、実演家が責任を負わされるかも知れません。まっとうなコミュニケーションを成立させるためには、元の声の持ち主と、生成AIを利用する者の存在、また議論に参加する者の所在が明確にされることが求められるのではないでしょうか。正規のルートで生成AIを使う場合も、実演家に生成物を検証する機会が設けられ、問題が起きた場合に備えてAIによる生成物の登録がなされるべきだと思われます。
 久保田氏
ありがとうございます。池水さんの提案は、真剣に考えるときに来ていると思います。法的な面でサポートできる点はないか、田邉さんからも意見をいただけますか。
田邉氏
内閣府知的財産戦略推進事務局では、図のような生成AIと知的財産権の望ましい関係のあり方を示しています。
久保田氏
ありがとうございます。池水さんの提案は、真剣に考えるときに来ていると思います。法的な面でサポートできる点はないか、田邉さんからも意見をいただけますか。
田邉氏
内閣府知的財産戦略推進事務局では、図のような生成AIと知的財産権の望ましい関係のあり方を示しています。
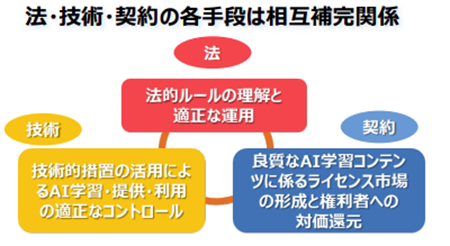 内閣府知的財産権略推進事務局 AI時代の知的財産権検討会 中間とりまとめについて【概要】p6より
2024年6月4日に、知的財産戦略本部が策定した「知的財産推進計画2024」18頁及び「新たなクールジャパン戦略」31頁に以下のような記載があります。
内閣府知的財産権略推進事務局 AI時代の知的財産権検討会 中間とりまとめについて【概要】p6より
2024年6月4日に、知的財産戦略本部が策定した「知的財産推進計画2024」18頁及び「新たなクールジャパン戦略」31頁に以下のような記載があります。
 個人的には「声」の保護を明確にした立法の必要性は高いと考えています。ただし、実際に見直しが記載されていたとしても、いつ改正されるかは不透明です。パブリシティ権の立法化などが望まれるところですが、そのハードルは高いと思います。
法律での対処には時間がかかり、その間に状況は進んでしまうことが想定されるため、契約などビジネス市場における対応や技術的な観点の重要性が高くなります。実際に、著名な声優である梶裕貴さんが自らの声を学習させた音声合成ソフトを製品化したり、大手声優事務所の青二プロダクションとAI音声プラットフォームサービスを提供するCoeFontがパートナーシップを締結し、多言語化したAI音声を音声アシスタントやロボット・音声ナビゲーションなどへ提供していくと発表しています。さらに、日本音声AI学習データ認証サービス機構というAI学習用の音声データやAI開発プロセスを管理するシステムの構築を目指す団体も設立されています。
声優さんの声に対する考え方は、AIで使われても問題ないという方もいらっしゃるでしょうし、絶対に嫌だという方もいらっしゃると思います。そういった個人個人の考え方を尊重しながら、それを踏まえた開発が行われる社会を実現していきたいと思い、私もこの団体の活動を手伝っています。
個人的には「声」の保護を明確にした立法の必要性は高いと考えています。ただし、実際に見直しが記載されていたとしても、いつ改正されるかは不透明です。パブリシティ権の立法化などが望まれるところですが、そのハードルは高いと思います。
法律での対処には時間がかかり、その間に状況は進んでしまうことが想定されるため、契約などビジネス市場における対応や技術的な観点の重要性が高くなります。実際に、著名な声優である梶裕貴さんが自らの声を学習させた音声合成ソフトを製品化したり、大手声優事務所の青二プロダクションとAI音声プラットフォームサービスを提供するCoeFontがパートナーシップを締結し、多言語化したAI音声を音声アシスタントやロボット・音声ナビゲーションなどへ提供していくと発表しています。さらに、日本音声AI学習データ認証サービス機構というAI学習用の音声データやAI開発プロセスを管理するシステムの構築を目指す団体も設立されています。
声優さんの声に対する考え方は、AIで使われても問題ないという方もいらっしゃるでしょうし、絶対に嫌だという方もいらっしゃると思います。そういった個人個人の考え方を尊重しながら、それを踏まえた開発が行われる社会を実現していきたいと思い、私もこの団体の活動を手伝っています。
 久保田氏
AI と共存した社会の実現という仕組みが作られて、それを後押しする形で法律が出てくる、という循環を期待したいです。それでは最後に、技術の面からのアプローチとして、鈴木さんからお話をいただけますか。
鈴木氏
AIに関しては、2024年に分類や定義の動きが進んでいます。AIのオープン性と完全性を評価して3段階に分類する仕組みとして、Model Openness Frameworkが発表されました。AI のモデルがどういう学習物を学習させて、最終的なAIモデルになったのかを3段階に分けてAIモデルがどれだけオープンなのかを示します。
レベル1:オープンサイエンス(最も開かれたレベル)
レベル2:ツールとデータの公開(モデルの一部を公開)
レベル3:モデルのブラックボックス(多くの商用AIサービス)
また、OSI による オープンソース AI の定義 v1.0も発表されました。その背景には、AIモデルの透明性と再現性の欠如があります。オープンソースを標榜しながら、制限的なライセンスを付与するAIが増加している懸念があるのです。AI を管理するために、 AI の学習物のリストを取っておく取り組みは、実務的に必要だと思います。そこで注目されているのがAI-BOM (AI Bill of Materials) です。
BOMは製造業で用いられてきた製品ごとの部品表を意味しています。ソフトウェア業界においても、SBOM (Software BOM)がOSSを中心に普及しつつあります。この仕組みをAIにおいても、透明性確保のためにAI-BOMとして普及する可能性が出てきています。AIの学習データのリストを記載し管理することがAI-BOMの目的のひとつとなっています。
AI-BOMでAI学習データを確認できるようになれば、犯罪的なコンテンツが学習されていないか、といったチェックが可能になります。コンテンツの著作権者にとっては、自分たちのコンテンツが勝手に学習されていないか確かめられます。AI-BOMは、ITで処理できるのでフォーマットが統一されれば自動的に判別できるようになります。将来的には、著作権者が学習物のリスクをチェックして、これだけ使用されているから請求できる、といった根拠になるでしょう。AI-BOMは、現場の人も使いやすくて、外部からの透明性が確保され、著作物の確認もできるという点で、その普及は非常に重要かなと考えます。
久保田氏
AI と共存した社会の実現という仕組みが作られて、それを後押しする形で法律が出てくる、という循環を期待したいです。それでは最後に、技術の面からのアプローチとして、鈴木さんからお話をいただけますか。
鈴木氏
AIに関しては、2024年に分類や定義の動きが進んでいます。AIのオープン性と完全性を評価して3段階に分類する仕組みとして、Model Openness Frameworkが発表されました。AI のモデルがどういう学習物を学習させて、最終的なAIモデルになったのかを3段階に分けてAIモデルがどれだけオープンなのかを示します。
レベル1:オープンサイエンス(最も開かれたレベル)
レベル2:ツールとデータの公開(モデルの一部を公開)
レベル3:モデルのブラックボックス(多くの商用AIサービス)
また、OSI による オープンソース AI の定義 v1.0も発表されました。その背景には、AIモデルの透明性と再現性の欠如があります。オープンソースを標榜しながら、制限的なライセンスを付与するAIが増加している懸念があるのです。AI を管理するために、 AI の学習物のリストを取っておく取り組みは、実務的に必要だと思います。そこで注目されているのがAI-BOM (AI Bill of Materials) です。
BOMは製造業で用いられてきた製品ごとの部品表を意味しています。ソフトウェア業界においても、SBOM (Software BOM)がOSSを中心に普及しつつあります。この仕組みをAIにおいても、透明性確保のためにAI-BOMとして普及する可能性が出てきています。AIの学習データのリストを記載し管理することがAI-BOMの目的のひとつとなっています。
AI-BOMでAI学習データを確認できるようになれば、犯罪的なコンテンツが学習されていないか、といったチェックが可能になります。コンテンツの著作権者にとっては、自分たちのコンテンツが勝手に学習されていないか確かめられます。AI-BOMは、ITで処理できるのでフォーマットが統一されれば自動的に判別できるようになります。将来的には、著作権者が学習物のリスクをチェックして、これだけ使用されているから請求できる、といった根拠になるでしょう。AI-BOMは、現場の人も使いやすくて、外部からの透明性が確保され、著作物の確認もできるという点で、その普及は非常に重要かなと考えます。
 久保田氏
AI-BOMはオープンソースを中心としたソフトウェアによる取り組みですが、人権そのものの情報をAI-BOMのような発想で技術の方がサポートすることも可能でしょうか。
鈴木氏
ソフトウェアのコードもAI学習に利用される「声」も、その創造には人が関わっています。オープンソースのコミュニティでは、開発者の権利を守るだけではなく、新しいコードを開発するための持続性を重要視しています。そのために、開発者の著作権を守り、使用の対価を還元して、コミュニティの維持と発展を目指しています。AI学習に関しても、コンテンツオーナーのことを考えないで、一方的に搾取するような形で収集し続けていけば、継続性が危ぶまれます。最終的には、利益を上げたいと思っている企業や生成者にとっても、デメリットになります。そうならないためには、エコシステムをうまく維持して、著作権者を含めて持続可能な仕組みを作っていくことが非常に重要です。その一助に、AI-BOMなどの仕組みがうまく活用されてほしいと思います。
久保田氏
ありがとうございます。
OSSのコミュニティが、AIの透明性や著作権者を守る技術を追求していることに敬意を払います。
田邉さんは生成AIと知的財産権の望ましい関係として、法と技術と契約と示されましたが、私は、法と電子技術と教育も大切だと考えています。AIと教育現場というのも、これからの子供たちにどのように伝えていけばいいのか、我々大人がしっかり考えないといけないと思います。使い方を間違えれば、とんでもないことになります。そういう観点から著作権教育や情報教育についても、これからみなさんと一緒にソフトウェア業界の強みを活かして議論していきたいと思います。
久保田氏
AI-BOMはオープンソースを中心としたソフトウェアによる取り組みですが、人権そのものの情報をAI-BOMのような発想で技術の方がサポートすることも可能でしょうか。
鈴木氏
ソフトウェアのコードもAI学習に利用される「声」も、その創造には人が関わっています。オープンソースのコミュニティでは、開発者の権利を守るだけではなく、新しいコードを開発するための持続性を重要視しています。そのために、開発者の著作権を守り、使用の対価を還元して、コミュニティの維持と発展を目指しています。AI学習に関しても、コンテンツオーナーのことを考えないで、一方的に搾取するような形で収集し続けていけば、継続性が危ぶまれます。最終的には、利益を上げたいと思っている企業や生成者にとっても、デメリットになります。そうならないためには、エコシステムをうまく維持して、著作権者を含めて持続可能な仕組みを作っていくことが非常に重要です。その一助に、AI-BOMなどの仕組みがうまく活用されてほしいと思います。
久保田氏
ありがとうございます。
OSSのコミュニティが、AIの透明性や著作権者を守る技術を追求していることに敬意を払います。
田邉さんは生成AIと知的財産権の望ましい関係として、法と技術と契約と示されましたが、私は、法と電子技術と教育も大切だと考えています。AIと教育現場というのも、これからの子供たちにどのように伝えていけばいいのか、我々大人がしっかり考えないといけないと思います。使い方を間違えれば、とんでもないことになります。そういう観点から著作権教育や情報教育についても、これからみなさんと一緒にソフトウェア業界の強みを活かして議論していきたいと思います。
 ●クロージングと懇親会
パネルディスカッションの閉会後には、パネリストと参加者による懇親会が開催されました。開催の冒頭では、新たに理事に就任したサイバートラスト(株)の眞柄 泰利氏が挨拶しました。
●クロージングと懇親会
パネルディスカッションの閉会後には、パネリストと参加者による懇親会が開催されました。開催の冒頭では、新たに理事に就任したサイバートラスト(株)の眞柄 泰利氏が挨拶しました。
 生成AIによって下書きした挨拶文を読み上げた後、AI技術の進歩と著作権の保護に向けて、ACCSが活動していく重要性を来場者に訴えました。
生成AIによって下書きした挨拶文を読み上げた後、AI技術の進歩と著作権の保護に向けて、ACCSが活動していく重要性を来場者に訴えました。
 ←中編へ
←中編へ
- 年度を選択
- 2000(平成12)年度(3件)
- 2001(平成13)年度(5件)
- 2002(平成14)年度(9件)
- 2003(平成15)年度(11件)
- 2004(平成16)年度(15件)
- 2005(平成17)年度(14件)
- 2006(平成18)年度(14件)
- 2007(平成19)年度(42件)
- 2008(平成20)年度(37件)
- 2009(平成21)年度(34件)
- 2010(平成22)年度(29件)
- 2011(平成23)年度(19件)
- 2012(平成24)年度(28件)
- 2013(平成25)年度(28件)
- 2014(平成26)年度(31件)
- 2015(平成27)年度(28件)
- 2016(平成28)年度(14件)
- 2017(平成29)年度(6件)
- 2018(平成30)年度(9件)
- 2019(令和元)年度(12件)
- 2020(令和2)年度(9件)
- 2021(令和3)年度(8件)
- 2022(令和4)年度(17件)
- 2023(令和5)年度(7件)
- 2024(令和6)年度(31件)
- 2025(令和7)年度(12件)
- 2026(令和8)年度(1件)